Holomorphic Embedding¶
First introduced by Antonio Trias in 2012 [1], promises to be a non-divergent power flow method. Trias originally developed a version with no voltage controlled nodes (PV), in which the convergence properties are excellent (With this software try to solve any grid without PV nodes to check this affirmation).
The version programmed in GridCal has been adapted from the master thesis of Muthu Kumar Subramanian at the Arizona State University (ASU) [2]. This version includes a formulation of the voltage controlled nodes. My experience indicates that the introduction of the PV control deteriorates the convergence properties of the holomorphic embedding method. However, in many cases, it is the best approximation to a solution. especially when Newton-Raphson does not provide one.
GridCal’s integration contains a vectorized version of the algorithm. This means that the execution in python is much faster than a previous version that uses loops.
Concepts¶
All the power flow algorithms until the HELM method was introduced were iterative and recursive. The helm method is iterative but not recursive. A simple way to think of this is that traditional power flow methods are exploratory, while the HELM method is a planned journey. In theory the HELM method is superior, but in practice the numerical degeneration makes it less ideal.
The fundamental idea of the recursive algorithms is that given a voltage initial point (1 p.u. at every node, usually) the algorithm explores the surroundings of the initial point until a suitable voltage solution is reached or no solution at all is found because the initial point is supposed to be far from the solution.
On the HELM methods, we form a curve that departures from a known mathematically exact solution that is obtained from solving the grid with no power injections. This is possible because with no power injections, the grid equations become linear and straight forward to solve. The arriving point of the curve is the solution that we want to achieve. That curve is best approximated by a Padè approximation. To compute the Padè approximation we need to compute the coefficients of the unknown variables, in our case the voltages (and possibly the reactive powers at the PV nodes).
The HELM formulation consists in the derivation of formulas that enable the calculation of the coefficients of the series that describes the curve from the mathematically know solution to the unknown solution. Once the coefficients are obtained, the Padè approximation computes the voltage solution at the end of the curve, providing the desired voltage solution. The more coefficients we compute the more exact the solution is (this is true until the numerical precision limit is reached).
All this sounds very strange, but it works ;)
If you want to get familiar with this concept, you should read about the homotopy concept. In practice the continuation power flow does the same as the HELM algorithm, it takes a known solution and changes the loading factors until a solution for another state is reached.
Fundamentals¶
The fundamental equation that defines the power flow problem is:
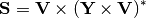
Most usefully represented like this:
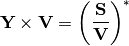
The holomorphic embedding is to insert a “travelling” parameter  , such
that for
, such
that for  we have an mathematically exact solution of the problem (but
not the solution we’re looking for…), and for
we have an mathematically exact solution of the problem (but
not the solution we’re looking for…), and for 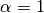 we have the solution
we’re looking for. The other thing to do is to represent the variables to be computed
as McLaurin series. Let’s go step by step.
we have the solution
we’re looking for. The other thing to do is to represent the variables to be computed
as McLaurin series. Let’s go step by step.
For we say that 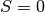 , in this way the
base equation becomes linear, and its solution is mathematically exact.
But for that to be useful in our case we need to split the admittance matrix
, in this way the
base equation becomes linear, and its solution is mathematically exact.
But for that to be useful in our case we need to split the admittance matrix 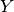 into
into 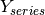 and
and 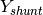 . is a diagonal matrix,
so it can be expressed as a vector instead (no need for matrix-vector product).
. is a diagonal matrix,
so it can be expressed as a vector instead (no need for matrix-vector product).
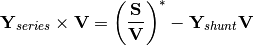
This is what will allow us to find the zero “state” in the holomorphic series
calculation. For we say that 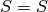 , so we don’t know the voltage
solution, however we can determine a path to get there:
, so we don’t know the voltage
solution, however we can determine a path to get there:
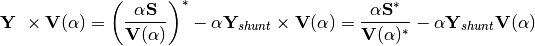
Wait, what?? did you just made this stuff up??, well so far my reasoning is:
- The voltage
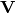 is what I have to convert into a series, and the
is what I have to convert into a series, and the - series depend of , so it makes sense to say that ,
as it is dependent of , becomes
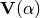 .
.
- The voltage
- Regarding the that multiplies
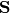 , the amount of power
, the amount of power - (
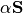 ) is what I vary during the travel from
to , so that is why S has to be accompanied by
the traveling parameter .
) is what I vary during the travel from
to , so that is why S has to be accompanied by
the traveling parameter .
- Regarding the
- In my opinion the
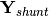 is to provoke the first
is to provoke the first - voltage coefficients to be one.
![\textbf{Y}_{series} \times \textbf{V}[0] = 0](../../_images/math/83ccf0828da7b5182f36a8b8f46d4d34b6ade571.png) , makes
, makes ![V[0]=1](../../_images/math/f09d3c84bfde91653c013cdc76156a3596ca0179.png) . This is
essential for later steps (is a condition to be able to use Padè).
. This is
essential for later steps (is a condition to be able to use Padè).
- In my opinion the
The series are expressed as McLaurin equations:
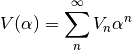
Theorem - Holomorphicity check There’s still something to do. The magnitude
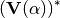 has to be converted into
has to be converted into
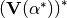 . This is done in order to make the
function be holomorphic. The holomorphicity condition is tested by the
Cauchy-Riemann condition, this is
. This is done in order to make the
function be holomorphic. The holomorphicity condition is tested by the
Cauchy-Riemann condition, this is
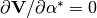 , let’s check that:
, let’s check that:
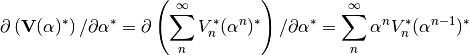
Which is not zero, obviously. Now with the proposed change:
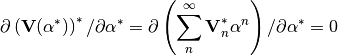
Yay!, now we’re mathematically happy, since this stuff has no effect in practice because our $alpha$ is not going to be a complex parameter, but for sake of being correct the equation is now:
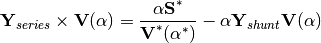
(End of Theorem)
The fact that 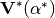 is dividing is problematic. We need to
express it as its inverse so it multiplies instead of divide.
is dividing is problematic. We need to
express it as its inverse so it multiplies instead of divide.
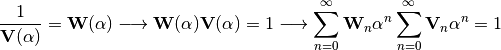
Expanding the series and identifying terms of we obtain the expression
to compute the inverse voltage series coefficients:
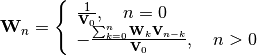
Now, this equation becomes:
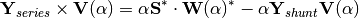
Substituting the series by their McLaurin expressions:

Expanding the series an identifying terms of we obtain the expression
for the voltage coefficients:
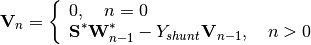
This is the HELM fundamental formula derivation for a grid with no voltage controlled nodes (no PV nodes). Once a sufficient number of coefficients are obtained, we still need to use the Padè approximation to get voltage values out of the series.
In the previous formulas, the number of the bus has not been explicitly detailed. All
the and the  are matrices of dimension
are matrices of dimension
 (number of coefficients by number of buses in the grid) This
structures are depicted in the figure
Coefficients Structure. For instance
(number of coefficients by number of buses in the grid) This
structures are depicted in the figure
Coefficients Structure. For instance
 is the
is the 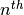 row of the coefficients structure
.
row of the coefficients structure
.
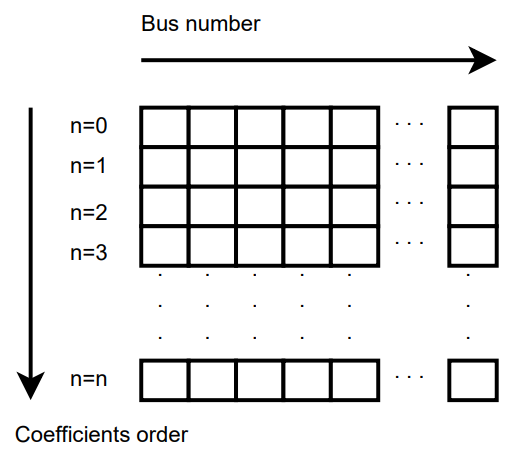
Coefficients Structure
Padè approximation¶
The McLaurinV equation provides us with an expression to obtain the voltage from
the coefficients, knowing that for we get the final voltage results.
So, why do we need any further operation?, and what is this Padè thing?
Well, it is true that the McLaurinV equation provides an approximation of the voltage by means of a series (this is similar to a Taylor approximation), but in practice, the approximation might provide a wrong value for a given number of coefficients. The Padè approximation accelerates the convergence of any given series, so that you get a more accurate result with less coefficients. This means that for the same series of voltage coefficients, using the McLaurinV equation could give a completely wrong result, whereas by applying Padè to those coefficients one could obtain a fairly accurate result.
The Padè approximation is a rational approximation of a function. In our case the
function is , represented by the coefficients structure
. The approximation is valid over a small domain of the function, in
our case the domain is ![\alpha=[0,1]](../../_images/math/6e4b89a8e1ed2058feb6049ebd48aa9a6259e155.png) . The method requires the function to be
continuous and differentiable for . Hence the Cauchy-Riemann condition.
And yes, our function meets this condition, we tested it before.
. The method requires the function to be
continuous and differentiable for . Hence the Cauchy-Riemann condition.
And yes, our function meets this condition, we tested it before.
GridCal implements two algorithms that perform the Padè approximation; The Padè canonical algorithm, and Wynn’s Padè approximation.
Padè approximation algorithm
The canonical Padè algorithm for our problem is described by:
![Voltage\_value\_approximation = \frac{P_N(\alpha)}{Q_M(\alpha)} \quad \forall \alpha \in [0,1]](../../_images/math/f06b01d95e553f736034c76d63cf4c56d64625c1.png)
Here 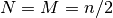 , where
, where 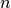 is the number of available voltage coefficients,
which has to be an even number to be exactly divisible by
is the number of available voltage coefficients,
which has to be an even number to be exactly divisible by 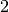 .
. 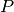 and
and
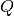 are polynomials which coefficients
are polynomials which coefficients 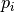 and
and 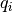 must be
computed. It turns out that if we make the first term of
must be
computed. It turns out that if we make the first term of 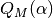 be
be
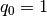 , the function to be approximated is given by the McLaurin expression
(What a happy coincidence!)
, the function to be approximated is given by the McLaurin expression
(What a happy coincidence!)
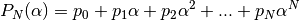
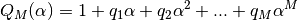
The problem now boils down to find the coefficients and . This
is done by solving two systems of equations. The first one to find which
does not depend on , and the second one to get which does depend
on .
First linear system: The only unknowns are the coefficients.
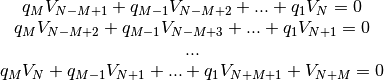
Second linear System: The only unknowns are the coefficients.
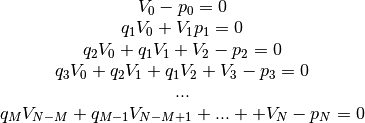
Once the coefficients are there, you would have defined completely the polynomials
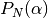 and , and it is only a matter of evaluating the
Padè approximation equation for .
and , and it is only a matter of evaluating the
Padè approximation equation for .
This process is done for every column of coefficients
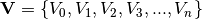 of the structure depicted in the
coefficients structure figure. This means that we have
to perform a Padè approximation for every node, using the one columns of the voltage
coefficients per Padé approximation.
of the structure depicted in the
coefficients structure figure. This means that we have
to perform a Padè approximation for every node, using the one columns of the voltage
coefficients per Padé approximation.
Wynn’s Padè approximation algorithm
Wynn published a paper in 1969 [4] where he proposed a simple calculation method to obtain the Padè approximation. This method is based on a table. Weniger in 1989 publishes his thesis [5] where a faster version of Wynn’s algorithm is provided in Fortran code.
That very Fortran piece of code has been translated into Python and included in GridCal.
One of the advantages of this method over the canonical Padè approximation implementation is that it can be used for every iteration. In the beginning I thought it would be faster but it turns out that it is not faster since the amount of computation increases with the number of coefficients, whereas with the canonical implementation the order of the matrices does not grow dramatically and it is executed the half of the times.
On top of that my experience shows that the canonical implementation provides a more consistent convergence.
Anyway, both implementations are there to be used in the code.
Formulation with PV nodes¶
The section Fundamentals introduces the canonical HELM algorithm. That algorithm does not include the formulation of PV nodes. Other articles published on the subject feature PV formulations that work more or less to some degree. The formulation below is a formulation corrected by myself from a formulation contained here [3], which does not work as published, hence the correction.
Embedding
The following embedding equations are proposed instead of the canonical HELM equations from section Fundamentals.
For Slack nodes:
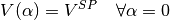
For PQ nodes:
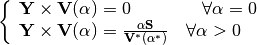
For PV nodes:
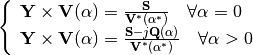
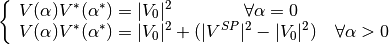
This embedding translates into the following formulation:
Step 1
The formulas are adapted to exemplify a 3-bus system where the bus1 is a slack, the bus 2 is PV and the bus 3 is PQ. This follows the example of the Appendix A of [3].
Compute the initial no-load solution ( ):
):
![\begin{bmatrix}
1 & 0 & 0 & 0 & 0 & 0\\
0 & 1 & 0 & 0 & 0 & 0\\
G_{21} & -B_{21} & G_{22} & -B_{22} & G_{23} & -B_{23}\\
B_{21} & G_{21} & B_{22} & G_{22} & B_{23} & G_{23}\\
G_{31} & -B_{31} & G_{32} & -B_{32} & G_{33} & -B_{33}\\
B_{31} & G_{31} & B_{32} & G_{32} & B_{33} & G_{33}\\
\end{bmatrix}
\times
\begin{bmatrix}
V[n]_{re, 1}\\
V[n]_{im, 1}\\
V[n]_{re, 2}\\
V[n]_{im, 2}\\
V[n]_{re, 3}\\
V[n]_{im, 3}\\
\end{bmatrix}
=
\begin{bmatrix}
V^{SP}_{re, 1}\\
V^{SP}_{im, 1}\\
0\\
0\\
0\\
0\\
\end{bmatrix}
\quad \forall n = 0](../../_images/math/b92fc2cc9dd28218ba5b292599e316f144672468.png)
Form the solution vector ![\textbf{V}[n]](../../_images/math/b200f87f11bf0e988f008ceac9b8eeffdc93af96.png) you can compute the buses calculated
power and then get the reactive power at the PV nodes to initialize
you can compute the buses calculated
power and then get the reactive power at the PV nodes to initialize
![\textbf{Q}[0]](../../_images/math/c251beab89cc9a71ba4cab545da7fda8fdb9aac7.png) :
:
![\textbf{S} = \textbf{V}[0] \cdot (\textbf{Y}_{bus} \times \textbf{V}[0])^*](../../_images/math/60bbcd32b82560775668f5eb03b4c35b8532a17a.png)
![\textbf{Q}_i[0] = imag(\textbf{S}_{i}) \quad \forall i \in PV](../../_images/math/94e508cc36e0cf8357a7f0bb3a14ebdb8cf49133.png)
The initial inverse voltage coefficients ![\textbf{W}[0]](../../_images/math/ceeebf609bb64d872f11bf9883a7aca5f4901480.png) are obtained by:
are obtained by:
![W_i[0] = \frac{1}{V_i[0]} \quad \forall i \in N](../../_images/math/05f1ed65a50250290cb2ef41074dd62e7e59abd9.png)
This step is entirely equivalent to find the no load solution using the Z-Matrix reduction.
Step 2
Construct the system of equations to solve the coefficients of order greater than zero
( ). Note that the matrix is the same as constructed for the previous step,
but adding a column and a row for each PV node to account for the reactive power
coefficients. In our 3-bus example, there is only one PV node, so we add only one
column and one row.
). Note that the matrix is the same as constructed for the previous step,
but adding a column and a row for each PV node to account for the reactive power
coefficients. In our 3-bus example, there is only one PV node, so we add only one
column and one row.
![\begin{bmatrix}
1 & 0 & 0 & 0 & 0 & 0 & 0\\
0 & 1 & 0 & 0 & 0 & 0 & 0\\
G_{21} & -B_{21} & G_{22} & -B_{22} & G_{23} & -B_{23} & W[0]_{im}\\
B_{21} & G_{21} & B_{22} & G_{22} & B_{23} & G_{23} & W[0]_{re}\\
G_{31} & -B_{31} & G_{32} & -B_{32} & G_{33} & -B_{33} & 0\\
B_{31} & G_{31} & B_{32} & G_{32} & B_{33} & G_{33} & 0\\
0 & 0 & V[0]_{re} & V[0]_{im} & 0 & 0 & 0\\
\end{bmatrix}
\times
\begin{bmatrix}
V[n]_{re, 1}\\
V[n]_{im, 1}\\
V[n]_{re, 2}\\
V[n]_{im, 2}\\
V[n]_{re, 3}\\
V[n]_{im, 3}\\
Q_2[n]\\
\end{bmatrix}
=
\begin{bmatrix}
0\\
0\\
f2_{re}\\
f2_{im}\\
f1_{re}\\
f1_{im}\\
\epsilon[n]\\
\end{bmatrix}
\quad \forall n > 0](../../_images/math/1e2257c70ba8d71431a7049ab104173ff773a296.png)
Where:
![f1 = S^*_i \cdot W^*_i[n-1] \quad \forall i \in PQ](../../_images/math/740036175b308ebf1d57f937c13ec57f503e778b.png)
![f2 = P_i \cdot W^*_i[n-1] + conv(n, Q_i, W^*_i) \quad \forall i \in PV](../../_images/math/b0fd5ab7b7393916f80f9e0431306d28f3e65c78.png)
![\epsilon[n] = \delta_{n1} \cdot \frac{1}{2} \left(|V_i^SP|^2 - |V_i[0]|^2\right) - \frac{1}{2} conv(n, V_i, V_i^*) \quad \forall i \in PV, n > 0](../../_images/math/4a54ba87066bbaf6a36b334e2e9295b429df9468.png)
The convolution  is defined as:
is defined as:
![conv(n, A, B) = \sum_{m=0}^{n-1} A[m] \cdot B[n-m]](../../_images/math/a30d43819d161b493f735f261b8e2ad6b1818080.png)
The system matrix ( ) is the same for all the orders of ,
therefore we only build it once, and we factorize it to solve the subsequent
coefficients.
) is the same for all the orders of ,
therefore we only build it once, and we factorize it to solve the subsequent
coefficients.
After the voltages and the reactive power at the PV nodes
![Q[n]](../../_images/math/035c392a37fe7de716d6d439f669de8e6d9c3070.png) is obtained solving the linear system (this equation), we must solve
the inverse voltage coefficients of order for all the buses:
is obtained solving the linear system (this equation), we must solve
the inverse voltage coefficients of order for all the buses:
![W_i[n] = \frac{- {\sum_{m=0}^{n}W_i[m] \cdot V_i[n-m]} }{V_i[0]} \quad \forall i \in N, n>0](../../_images/math/6e1a4e52427af02cd82fc84b0bb9b4336a0baf01.png)
Step 3
Repeat step 2 until a sufficiently low error is achieved or a maximum number of iterations (coefficients).
The error is computed by comparing the calculated power (eq
Scalc) with the specified power injections 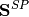 :
:
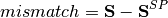
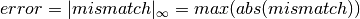
| [1] | Trias, Antonio. “The holomorphic embedding load flow method.” Power and Energy Society General Meeting, 2012 IEEE. IEEE, 2012. |
| [2] | Subramanian, Muthu Kumar. Application of holomorphic embedding to the power-flow problem. Diss. Arizona State University, 2014. |
| [3] | (1, 2) Liu, Chengxi, et al. “A multi-dimensional holomorphic embedding method to solve AC power flows.” IEEE Access 5 (2017): 25270-25285. |
| [4] | Wynn, P. “The epsilon algorithm and operational formulas of numerical analysis.” Mathematics of Computation 15.74 (1961): 151-158. |
| [5] | Weniger, Ernst Joachim. “Nonlinear sequence transformations for the acceleration of convergence and the summation of divergent series.” Computer Physics Reports 10.5-6 (1989): 189-371. |